Building a Second Brain (the hacker's way)
Overview
I've been intrigued by the idea of a Second Brain / Zettelkasten for a couple of years now, probably since first hearing about Roam Research. If you're unfamiliar with the concept, good places to start are here and here.
Second Brain is essentially a buzzword for a note-organization method - the idea is that you can record notes in a way that not only helps retain and look up information, but also allows you to find relationships between ideas more effectively by linking those notes together in a specific way. Those relationships, in turn, help synthesize new ideas - at least, in theory.
The notion of unlocking hidden potential via digital note-taking became so captivating that it sparked the development of about half a dozen specialized commercial tools - there's the aforementioned Roam, the widely-known Notion, but also Reflect, Obsidian, Athens Research, and others. Apart from the Zettelkasten-like bi-directional links, the big feature they offer is multiplayer. If the value of multiplayer for creative tools wasn't obvious before, it is now. The FOMO is strong and there's money to be made.
Essence
Let's ignore the flashy stuff for a second and try to solve this from first principles. Ideally, a modern digital note-taking tool would:
- provide a cross-reference view into data (e.g. via bi-directional links)
- respond to input instantly (fast search)
- implement a form of standardized version control
- address privacy & security concerns1:
- transparent data-handling policy
- secure access with optional data encryption
- provide a credible exit
- be cross-platform and "omnipresent" (desktop+mobile client, cloud-stored data)
- allow for opt-in collaboration
I intentionally put multiplayer very low on that list. No need to hammer the nails with a microscope if all you need is a personal knowledge-management tool. For that use case, there are editor/IDE solutions like Foam (for VSCode) and Org-roam (for Emacs). They are localhost by default, completely free, and the upside of not having to collaborate with others is that you get to be picky about data-sharing as well. For instance, you may decide to only use GitHub for version control and centralized storage, or even keep the (backed-up) repo on a hard drive and opt out of cloud services completely.
Second Brain, Unix-style
After playing a bit with the commercial tools (Roam, then Reflect - stopped due to vendor lock-in concerns) I tried both Foam and Org-roam and liked the experience2. What I found especially handy is that on top of all the functionality I could work with my notes inside the editor I was already using every day - integrating note management into the daily routine was effortless.
What I failed to consider, however, is that as soon as I decided to switch my editor of choice I had to manually strip the implementation-specific metadata from my notes - for the link graph to work, Foam, for instance, uses Wikilinks. To be fair, Foam's way of honoring the credible exit pledge is to provide compatibility via Link Reference Definitions, but that still requires betting the farm on Markdown.
As far as the trade-offs go this is a pretty reasonable one, but the purist in me still protests. Markdown doesn't come for free. It demands specific formatting which you need to read in a separate view to visually parse - writing and reading markdown are separate modes.
At the same time, the value it provides for that is not very useful for my use case. Most of my notes are nested lists of short paragraphs of plain text - there's no need for headings (list hierarchy takes care of that) or even rich-formatted links (copying and pasting text is not that hard). So all I really need is to have one big data structure with a somewhat loose hierarchy of single-sentence text atoms, which I could then view as flattened and grouped by some criteria to get insights.
If you define the problem like this, the implementation becomes trivial. First,
all notes are merged into a single .txt file3. This way the data is easily readable and editable
in its rawest form. Everything is inside one giant list, items with obvious
hierarchical relationships are nested accordingly. Notes that have no obvious
connection just sit side-by-side on the top level as separate tree branches.
- ...
- travel schedule 2023
- 20230423 New York
- 20230506 Berlin
- 20230719 Paris
- currently reading
- The Seven Wonders of the Ancient World
- Great Pyramid of Giza
- constructed circa 2570 BC
- 4th dynasty
- height 146.6m
- The Hanging Gardens of Babylon
- Ishtar Gate
- built circa 575 BCE
- by order of King Nebuchadnezzar II
- Reconstruction located in Pergamon Museum in Berlin
- ...
- ...
The file is committed to git, mostly for the backup value - you're less afraid to delete stuff if you can restore it later.
Cross-referencing notes can be done via a fuzzy search program - ideally, one
that shows not only the matched line (the way grep does) but also the surrounding context.
Since I use neovim, I'm achieving this with
Telescope:
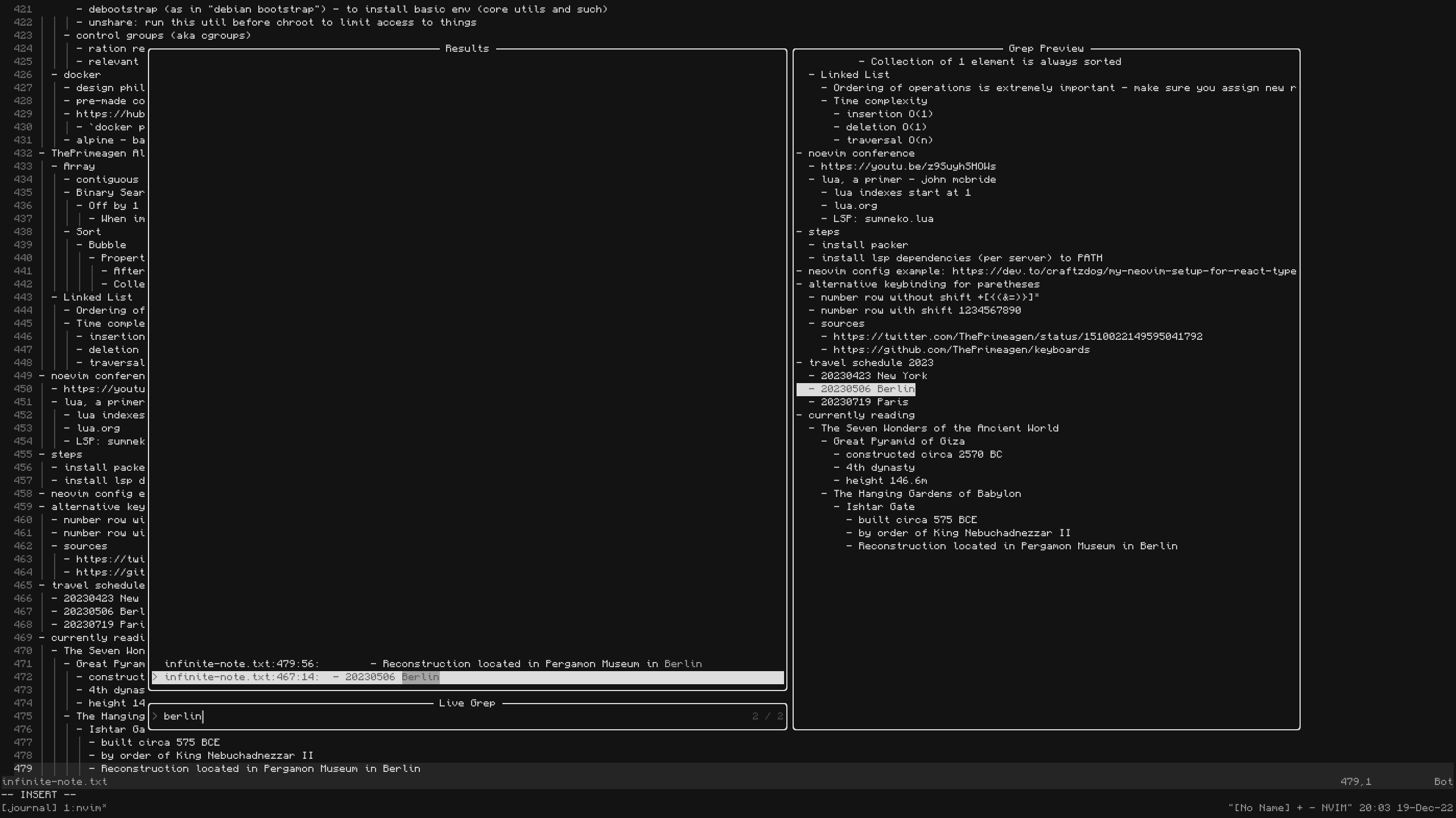
On the left I can navigate up/down the list of all matches in the file, the surroundings for wider context are visible on the right.
Closing Thoughts
Is this better than linking files with metadata? Well, there are pros and cons.
Bi-directional tagging requires manual metadata management and linking - at least until that is automated by AI-assisted tools4. That approach allows for some search optimizations as you control what's worthy of indexing and what's not.
With fuzzy search over a minimal but consistent plain-text tree, everything is auto-linked to potentially everything else. The obvious downside is search performance when the note gets large enough. In practice, I'm yet to hit that limit.
Footnotes
-
I don't want to be preachy about internet privacy - at the end of the day, everyone decides for themselves how much they are comfortable exposing. What's non-negotiable, I think, is that a) the contract with the third-party providers must be transparent and b) there's always an option to go the open-protocol, Unix-style DIY way. Since the specifics for the open protocols in this space are yet to be figured out, simplicity of implementation seems to be the most futureproof. ↩
-
Foam in particular utilizes an interesting approach of "software as curation" - instead of writing your own tool from scratch, you compose it from separate open-source packages. I dug a little in their git log and most of the early commits are just concept docs for how the pieces should fit together, no code at all. Pretty neat. ↩
-
I'm calling mine
infinite-note.txtand it reminds me of the Turing machine. ↩ -
Given the achievements we saw in the machine learning space this year I wouldn't be surprised if by the end of 2023 that is a feature in at least one of the commercial tools I've listed. ↩